通过上两篇文章的反馈,感觉逐字句的翻译,读者很难读下去。从这篇文章开始,我会用简练的语言,对这本书进行拆解,方便读者快速的掌握知识脉络。
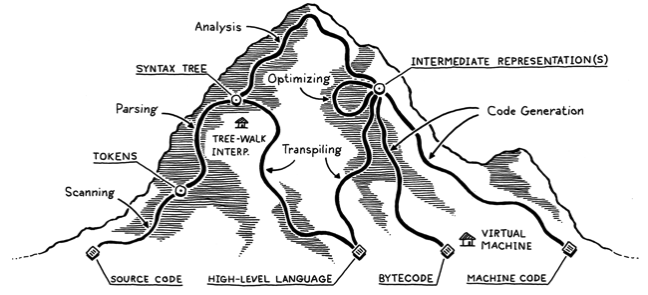
编译器全景图
对于一个编译器的主要任务是将我们写的源代码翻译成一个机器可以执行的代码,当然,在做这个过程中也可能会编译成中间代码,或者是字节码。每一种编码都有其特殊的目的和意义。在下面这个全景图中展示了这些路径。我们将循着这些路径完成我们的编译器之旅。
扫描(语义分析)
第一个需要进行的就是将我们写的源代码进行语义分析。例如我们有如下一个源码:
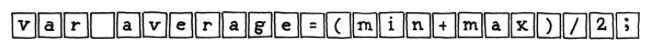
编译器首先按照某种规则将源码一段一段的读进来,然后将一句话分成不同的 token,在这个语句中有一些没有用的词,比如空格以及后面的分号。经过扫描器,我们得到了这样的内容。

我们自己做一个编程语言,这次我们自己尝试做一个脚本语言,主要是对源代码做解释执行。如果我们使用 Java 开发我们的编译器,我们应该第一步进行扫描。
package com.craftinginterpreters.lox;
import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.nio.charset.Charset;import java.nio.file.Files;import java.nio.file.Paths;import java.util.List;
public class Lox { public static void main(String[] args) throws IOException { if (args.length > 1) { System.out.println("Usage: jlox [script]"); System.exit(64); } else if (args.length == 1) { runFile(args[0]); } else { runPrompt(); } }}
private static void runFile(String path) throws IOException { byte[] bytes = Files.readAllBytes(Paths.get(path)); run(new String(bytes, Charset.defaultCharset())); }private static void runPrompt() throws IOException { InputStreamReader input = new InputStreamReader(System.in); BufferedReader reader = new BufferedReader(input);
for (;;) { System.out.print("> "); String line = reader.readLine(); if (line == null) break; run(line); } }
package com.craftinginterpreters.lox;
import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.nio.charset.Charset;import java.nio.file.Files;import java.nio.file.Paths;import java.util.List;
public class Lox { public static void main(String[] args) throws IOException { if (args.length > 1) { System.out.println("Usage: jlox [script]"); System.exit(64); } else if (args.length == 1) { runFile(args[0]); } else { runPrompt(); } }}
private static void runFile(String path) throws IOException { byte[] bytes = Files.readAllBytes(Paths.get(path)); run(new String(bytes, Charset.defaultCharset())); }private static void runPrompt() throws IOException { InputStreamReader input = new InputStreamReader(System.in); BufferedReader reader = new BufferedReader(input);
for (;;) { System.out.print("> "); String line = reader.readLine(); if (line == null) break; run(line); } }
复制代码
在这段代码中,首先将源码读进来,然后进行句子的分析。首先要将代码编程一个一个的词,然后分析每句话是否有语法错误。这里可以根据我们自己要求进行检查。具体实现,暂时不做过多的解释。
private static void run(String source) { Scanner scanner = new Scanner(source); List<Token> tokens = scanner.scanTokens();
// For now, just print the tokens. for (Token token : tokens) { System.out.println(token); } }
复制代码
如果我们有个语句是这样的:var l = “hello”;
这个语句中 var 是关键字。l 是变量名,hello 是给变量的值。对于这样一个简单的语句我们应该如何区分呢,首先我们应该有一个表,用来记录我们自己设计的编程语言中的一些内容
package com.craftinginterpreters.lox;
enum TokenType { // Single-character tokens. LEFT_PAREN, RIGHT_PAREN, LEFT_BRACE, RIGHT_BRACE, COMMA, DOT, MINUS, PLUS, SEMICOLON, SLASH, STAR,
// One or two character tokens. BANG, BANG_EQUAL, EQUAL, EQUAL_EQUAL, GREATER, GREATER_EQUAL, LESS, LESS_EQUAL,
// Literals. IDENTIFIER, STRING, NUMBER,
// Keywords. AND, CLASS, ELSE, FALSE, FUN, FOR, IF, NIL, OR, PRINT, RETURN, SUPER, THIS, TRUE, VAR, WHILE,
EOF}
复制代码
对于 var 他是属于 keywords,这样在后 main 的过程中,我们将会进行单独的处理。 = 这是一个二元的操作符。通过这样的区分,我们在后面的分析过程中将会对每一个语句进行合适的切割,实现一个树形的结构。
以上是一个最简单的语句的大致分析过程,下一个部分,将会试图解释一个长的语句是如何解析的。